Jurnal ditulis oleh :
Shuxin
Yang
School of Information Engineering,
Jiangxi University of Science and Technology,
Ganzhou 341000, China
Lanying
Shi
School of Information
Engineering,Jiangxi University of Science and Technology,
Ganzhou 341000, China
2013
Diterjemahkan oleh : Siti Kholifah
Pencarian kata kunci pada relasional
database memungkinkan pengguna untuk mendapatkan informasi dalam database secara
mudah hanya dengan memasukkan kata kunci tertentu. Namun sayangnya, sistem
prototipe yang ada saat ini masih menyajikan hasil dalam bentuk daftar linear.
Pengguna masih harus menelusuri secara individu untuk menemukan informasi yang benar-benar
dibutuhkan. Untuk mengatasi masalah ini, penelitian dilakukan dengan
mengelompokkan hasil untuk kata kunci pencarian pada relational database.
Belajar
dari konsep vektor dalam fisika, penelitian ini mengusulkan model baru dalam
bentuk result-tree, yang disebut karatekeristik vektor result-tree. Penelitian
ini juga mengusulkan strategi pengelompokan baru berdasarkan karatekeristik
vektor result-tree. Pada awalnya,
didapatkan informasi mengenai karakteristik result-tree, dan menjelaskan joint
tuple tree menggunakan vektor representasi, dan kemudian mengklasifikasikan
hasil pencarian sesuai dengan representasi vektor yang sesuai.
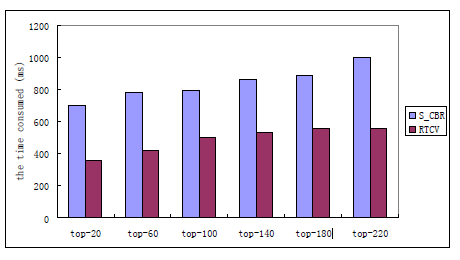
Perbandingan Waktu Konsumsi
Perbandingan Efek Pengelompokkan

Perbandingan yang dilakukan tidak
hanya menunjukkan kelayakan dan rasionalitas strategi pengelompokan yang
dihasilkan oleh metode penelitian ini, tetapi juga mem-verifikasi rasionalitas
dari konsep vektor karakteristik result
tree, karena mengintegrasikan informasi simpul (informasi konten) dan
informasi tepi (informasi struktur) dari result
tree. Sehingga dapat dipastikan bahwa result
tree pada satu cluster memenuhi hal-hal sebagai berikut:
(1)
Berisi tipe node yang sama, dan masing-masing jenis memiliki jumlah node yang
sama.
(2)
Mengandung jenis tepi yang sama, dan masing-masing jenis memiliki jumlah yang
sama dari tepi.
(3)
Berisi jumlah yang sama dan isi yang serupa dari informasi.
Metode
pengelompokan hasil untuk KSORD ini, sampai batas tertentu, dapat membantu meningkatkan
hasil pencarian, membantu pengguna menavigasi dan meningkatkan efisiensi
pencarian, serta memungkinkan pengguna untuk dengan cepat memahami informasi
hasil dan distribusi hasil pencarian secara keseluruhan
Sumber : Yang, Shuxin
& Shi, Lanying. (2013).Result Clustering for Keyword Search over Relational
Database. Journal of Software, Vol 8, No.12, December 2013.